WordCount(词频统计)就像是编程世界的Hello World程序,新手必备。另外几个经典的算法:倒排索引、页面排序、数据去重、TopN等一并记录如下。
WordCount
词频统计是MapRedurce编程的一个经典案例
继承Mapper类
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for(String word : words){
k.set(word);
context.write(k,v);
}
}
}
继承Reducer类
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//局部汇总
int count = 0;
for(IntWritable value : values){
count += value.get();
}
v.set(count);
context.write(key,v);
}
}
编写驱动类
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//通过Job来封装本次MR信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//指定驱动类、Mapper类、Reducer类
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//指定Mapper类的输出KV类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定Reducer类的输出KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入、输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交Job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
注意
- 这里驱动类里的输入输出路径没有写死,可以带参运行。
- Map类里的一点细节,尽量不要在map方法里反复创建对象。
InvertedIndex
倒排索引,简单地说就是:根据内容查文档,而不是根据文档查内容。
案例需求
输入
假设有三个txt文件,内容举例如下:
1.txt
a b c
a b b b b
hello world
hello b
其他文件内容类似
输出
要求输出文件的内容如下:
a 1.txt:2;2.txt:2;
b 2.txt:1;3.txt:1;1.txt:6;
c 1.txt:1;2.txt:1;
d 2.txt:1;
hello 1.txt:2;3.txt:1;
j 2.txt:1;
s 2.txt:1;
world 1.txt:1;
分析
- Map拿到手的内容举例如下:
<0,"a b c">
Map输出的内容形式如下:
<a:1.txt,1>
<a:1.txt,1>
<b:1.txt,1>
- 经过Map之后,单纯依靠后面的Reduce阶段,不能同时完成词频统计和生成文档列表,所以必须增加一次Combine阶段
Combine拿到的内容形式上就是Map输出的内容,Combine的输出内容形式如下:
<a,1.txt:2>
<b,1.txt:1>
其他文档的内容类似,里面也可能含有a、b等。
- Reduce阶段就只需将文件中相同key的value进行统计,组合成文档名加词频的形式就行
Reduce接收的内容形如Combine输出的内容,它输出内容的kv形式如下:
<a,1.txt:2;2.txt:3>
编程实现
Map
package com.gx.InvertedIndex;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
import java.util.StringTokenizer;
public class InvertedIndexMapper extends Mapper<LongWritable, Text,Text,Text> {
//存储单词和文档名称
private Text keyInfo = new Text();
//存储词频,初始化为1
private Text valueInfo = new Text("1");
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//得到这行数据所在的文件分片
FileSplit fileSplit = (FileSplit)context.getInputSplit();
//根据文件切片得到文件名
String fileName = fileSplit.getPath().getName();
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()){
keyInfo.set(itr.nextToken()+":"+fileName);
context.write(keyInfo,valueInfo);
}
}
}
Combine
package com.gx.InvertedIndex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class InvertedIndexCombiner extends Reducer<Text, Text,Text,Text> {
private Text keyInfo = new Text();
private Text valueInfo = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int sum = 0;//词频统计
for(Text value : values){
sum += Integer.parseInt(value.toString());
}
int splitIndex = key.toString().indexOf(":");
//重新设置key为单词
keyInfo.set(key.toString().substring(0,splitIndex));
//重新设置value为文档名加词频
valueInfo.set(key.toString().substring(splitIndex+1)+":"+sum);
context.write(keyInfo,valueInfo);
}
}
Reduce
package com.gx.InvertedIndex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class InvertedIndexReducer extends Reducer<Text,Text,Text,Text> {
private static Text valueInfo = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//生成文档列表
String fileList = new String();
for(Text value : values){
fileList += value.toString()+";";//注意这是分号,记录了单词所属的那些文档
}
valueInfo.set(fileList);
context.write(key,valueInfo);
}
}
易错点
- 各个阶段的KV类型一定要小心,没什么特别要求的话,可以统一为Text类型。这样后面的Driver类也可以简写。
- 在设置各个阶段的输出内容,也就是KV值时,为了防止出错,应该预先创建要输出的key对象和value对象,而不应该直接对本阶段输入的key对象进行处理,否则容易造成逻辑错误。(这是一次教训,就因为设置kv,造成了逻辑错误,程序运行结束,只有输出文件包,但没有结果文件,查了一个多小时的错。)
- 分割字符串时,可以考虑用StringTokenizer类。
PageRank
PageRank,网页排名,是Google专有的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。
原图
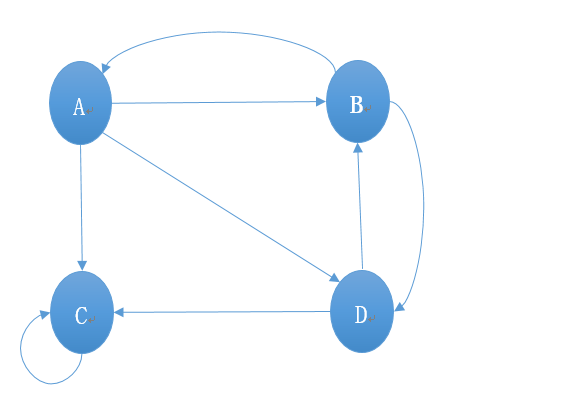
设计数据存储格式
输入
A 0.25 B C D
B 0.25 A D
C 0.25 C
D 0.25 B C
- 第一列代表当前网页
- 第二列代表当前网页PR值
- 之后的字母代表当前网页指向的链接网页
- 字符之间用一个空格隔开
输出
因为PageRank算法需要迭代计算,所以输出格式应与输入格式保持一致。
MapReduce编程实现
Map阶段
map得到的内容如下:
A 0.25 B C D
这里面有三类信息:
- 当前网页名,A
- A当前的PR值,0.25
- A指向的链接网页,B、C、D
map的输出内容如下:
A @B C D
B $0.0833
C $0.0833
D $0.0833
map的输出有两类:
- 继续保存当前网页的所有指向链接
- 各个被指向链接从当前网页得到的PR值
代码如下:
package com.gx.pagerank;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class PageRankMapper extends Mapper<LongWritable, Text,Text,Text> {
Text keyInfo = new Text();
Text valueInfo = new Text();
private String id;//记录网页名
private float pr;//网页PR值
private int count;//当前网页拥有的链接数
private float avg_pr;//当前网页分出去的平均PR值
@Override//输入<A,0.25 B C D>
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
id = itr.nextToken();
pr = Float.parseFloat(itr.nextToken());
count = itr.countTokens();
avg_pr = pr/count;
String linkIds = "@";
while (itr.hasMoreTokens()){
String linkId = itr.nextToken();
keyInfo.set(linkId);
valueInfo.set("$"+avg_pr);
linkIds += " " + linkId;
context.write(keyInfo,valueInfo);//第一种输出类型 <B,$0.0833>、<C,$0.0833>、<D,$0.0833>
}
keyInfo.set(id);
valueInfo.set(linkIds);
context.write(keyInfo,valueInfo);//第二种输出类型 <A,@ B C D>
}
}
Reduce阶段
从Map到Reduce,框架会自动将Key相同的Value合并
所以Reduce得到的内容如下:
A <@B C D,$0.125>
B <@A D,$0.125,$0.0833>
...
Reduce阶段就做两件事;
- 将以$开头的PR值进行求和计算,作为此次迭代的网页PR值
- 拼接各类字符,组成和输入格式一样的字符串输出
代码如下:
package com.gx.pagerank;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class PageRankReducer extends Reducer<Text, Text,Text, Text> {
private Text keyInfo = new Text();
private Text valueInfo = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
float pr = 0;
String link = "";
for(Text value : values){
if('$'==value.toString().charAt(0)){//以$开头
pr += Float.parseFloat(value.toString().substring(1));
}else {//以@开头
link += value.toString().substring(1);
}
}
pr = 0.8f * pr + 0.2f * 0.25f;//加入跳转因子,进行平滑处理。最后的0.25f其实是网页总数分之一
keyInfo.set(key);
valueInfo.set(pr+link);
context.write(keyInfo,valueInfo);
}
}
Driver
驱动类都是套路,唯一要注意的就是,PageRank算法需要迭代,在驱动类里需要增加一个循环,一般迭代三四十次就收敛了。这里只迭代3次,简单表示一下。
代码如下:
package com.gx.pagerank;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class PageRankDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String pathIn = "F:\\hadooptemp\\input3";
String pathOut = "F:\\hadooptemp\\output3";
for (int i = 0; i < 3; i++) {
Job job = Job.getInstance(conf);
job.setJarByClass(PageRankDriver.class);
job.setMapperClass(PageRankMapper.class);
job.setReducerClass(PageRankReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path(pathIn));
FileOutputFormat.setOutputPath(job,new Path(pathOut));
pathIn = pathOut;
pathOut = pathOut + i;
boolean result = job.waitForCompletion(true);
}
}
}
迭代三次后的输出内容如下:
A 0.12066667 B C D
B 0.15711111 A D
C 0.56511116 C
D 0.15711111 B C
总结
没有细说的两个问题
PageRank算法还有一些值得探讨的问题,这里没记录,比如Rank leak和Rank sink问题。简单说明一下:
- Rank leak:一个独立的网页如果没有外出的链接就产生等级泄漏
解决办法:
- 将无出度的节点递归的从图中去掉,待其他节点计算完毕后再添加。
- 对无出度的节点添加一条边,指向那些指向它的顶点。
- Rank sink:整个网页图中的一组紧密链接成环的网页如果没有外出的链接就产生Rank sink。
解决办法:
- 引入随机浏览模型。
一个网页PR值的计算公式
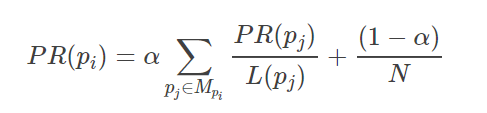
其中Mpi是所有对pi网页有出链的网页集合,L(pj)是网页pj的出链数目,N是网页总数,α一般取0.85。(上述代码里α取得是0.8,N为4)也就是这一行代码:
pr = 0.8f * pr + 0.2f * 0.25f;//加入跳转因子,进行平滑处理。最后的0.25f其实是网页总数分之一
要注意的细节问题
- 还是要对每一个阶段的KV值的设定格外注意。
- 注意变量的作用域,设为全局变量还是局部变量,道理很简单,但马虎了,不容易查错。就因为这个问题,查了一个小时的错。本来应该是局部变量,结果大意了,设为了全局变量,搞混了几个变量的作用域,导致程序结果错误。
DataDeduplication
数据去重就是去除重复数据的操作,较为简单。
输入文件格式
算法的思路是个大方向,但具体的编码要具体分析,比如要考虑数据的格式。这里数据的格式如下:
2019-2-1 a
2020-1-1 n
...
算法
- Map阶段:将key设为需要去重的数据,value设为空
- Reduce阶段:将得到的key继续复制为输出的key,value还是设为空
代码实现
Map
package com.gx.quchong;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text,Text,NullWritable> {
private static Text keyInfo = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
keyInfo = value;
context.write(keyInfo, NullWritable.get());
}
}
Reduce
package com.gx.quchong;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text, NullWritable,Text,NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
总结
数据去重算法本身较为简单,进一步体会MapReduce编程。
TopN
TopN分析法是指从研究对象中按照某一个指标进行倒序或正序排列,取其中所需的N个数据,并对这N个数据进行重点分析的方法。
算法
输入数据格式如下:
10 3 8 7
12 23 45 3 2
19 28 34
- Map阶段:可以用TreeMap来保存TopN的数据。另外,以往的Mapper都是处理一行数据之后就用context.write()方法输出,而现在需要包所有数据保存在TreeMap后再写入,所以把context.write()方法放在cleanup()里执行。cleanup()方法就是整个MapTask执行完毕后才执行的一个方法。
- Reduce阶段:汇总数据,取TopN数据即可。
编程实现
Map
package com.gx.topn;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.TreeMap;
public class TopnMapper extends Mapper<LongWritable, Text, NullWritable, IntWritable> {
private TreeMap<Integer,String> map = new TreeMap<Integer, String>();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] nums = line.split(" ");
for (String num : nums){
map.put(Integer.parseInt(num)," ");
if(map.size()>5){
map.remove(map.firstKey());
}
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
for (Integer i : map.keySet()){
try {
context.write(NullWritable.get(),new IntWritable(i));
}catch (Exception e){
e.printStackTrace();
}
}
}
}
Reduce
package com.gx.topn;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Comparator;
import java.util.TreeMap;
public class TopnReducer extends Reducer<NullWritable, IntWritable,NullWritable,IntWritable> {
private TreeMap<Integer,String> map = new TreeMap<Integer, String>(new Comparator<Integer>() {
public int compare(Integer a, Integer b) {
return b - a;
}
});
@Override
protected void reduce(NullWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
for (IntWritable value : values){
map.put(value.get()," ");
if (map.size()>5){
map.remove(map.firstKey());
}
}
for (Integer i : map.keySet()){
context.write(NullWritable.get(),new IntWritable(i));
}
}
}
总结
TopN算法本身不难,但可以将其作为一个模板,考虑对其进行改进。
>> Home